

Intelligence Artificielle – Deep Learning
Une évolution extrêmement rapide
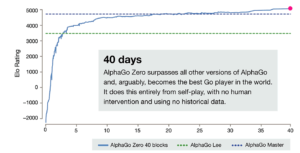
La recherche en IA progresse très rapidement. En mars 2016, Alpha Go Lee battait Lee Sedol, un des meilleurs joueurs de Go au monde, puis dans sa version Master, elle battait le champion du monde Ke Jie en mai 2017. Désormais, sa version Zero sait apprendre seule, joue à un niveau « super-humain », et peut seulement être battue par une autre IA (qui n’existe pas encore). Après avoir redécouvert seule les coups classiques connus par les joueurs humains, elle les a améliorés, puis elle a inventé les siens, et peut désormais nous apprendre à mieux jouer, comme les maitres enseignent à leurs élèves.

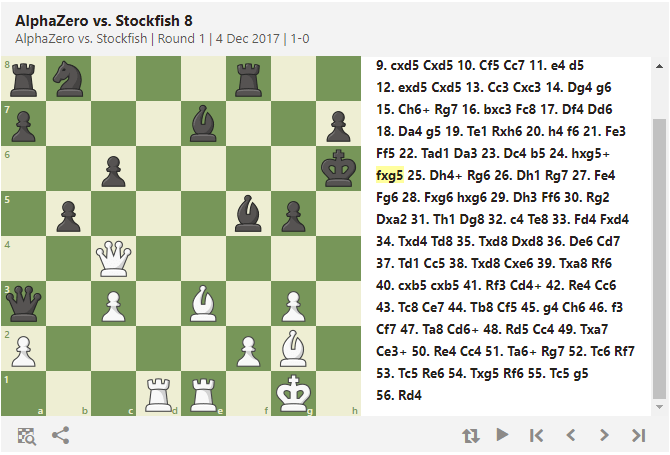
Depuis début décembre, Alpha Go Zero sait aussi jouer aux échecs, et montre là aussi une capacité de jeu non humaine d’après les experts, dans le sens où il ne joue pas comme un humain, ni comme un programme informatique habituel. Ici, on le voit battre le programme Stockfish 8 à plate couture, entre autres avec un coup génial, souligné en jaune :
Mi-août 2017, l’IA d’Elon Musk a battu les champions de DotA 2, le jeu multi-joueur le plus joué au monde en 2016, où 2 équipes de 5 joueurs doivent agir très vite en ayant une vision partielle du champ de bataille, et utiliser efficacement leurs pouvoirs et contrer ceux des adversaires, choisis parmi une large palette. Le défi était plus grand que le Go : jeu en équipe + diversité de coups possibles bien plus grande + réactivité en temps réel + vision partielle du terrain. Google et Deep Mind ont pour objectif de battre les champions à Starcraft, un jeu où on doit bâtir son armée et l’envoyer au combat. Côté Poker, c’est Libratus, développée par l’université de Carnegie Mellon, qui a battu les champions du monde à une version un contre un du « Texas Hold’em no limit ». Les joueurs professionnels se rassurent en se disant qu’elle ne gagne pas à une table de plusieurs joueurs : trop d’inconnues… Pour l’instant ! Et les exemples se multiplient, dans tous les domaines.
Récemment, Mark Zuckerberg, PDG de Facebook, et Elon Musk, PDG de SpaceX, Tesla, fondateur de Paypal, coprésident de OpenAI, se sont affrontés par tweets, sur le thème « faut-il avoir peur de l’IA ? », en évoquant la « singularité », ce moment où l’IA deviendra consciente et autonome. Bien que leurs sociétés investissent massivement dans cette technologie, le 1er pense que l’IA est bénéfique, alors que le 2nd pense que nous devons nous en méfier.
Que faut-il en penser ? Où en sommes-nous ? Les IA pensent-elles comme nous ? La singularité est-elle possible ? Le fait de programmer des IA peut-il nous en apprendre davantage sur nous-mêmes ? Que nous réserve l’avenir ? Le sujet, très riche, est autant technique que philosophique. Des auteurs de science-fiction comme Isaac Asimov ou des films comme Terminator ou Matrix ont-ils entrevu le futur ? On sent leur influence dans les débats actuels, même s’ils ne sont jamais évoqués explicitement.
Afin d’avoir les idées claires sur l’IA, il faut savoir comment elle fonctionne, et quelles en sont les limites actuelles. Cela permet de mesurer l’énorme chemin à parcourir avant que nous puissions créer des IA fortes, c’est-à-dire qui soient non seulement capables de produire un comportement intelligent, mais d’éprouver une impression d’une réelle conscience de soi, de « vrais sentiments » (quoi qu’on puisse mettre derrière ces mots), et « une compréhension de ses propres raisonnements ».
Machine learning – réseaux de neurones – deep learning
Le terme « machine learning » désigne les algorithmes par lesquels la machine « apprend » des choses qui n’ont pas été explicitement programmées, ie. Pour lesquels le programmeur n’a pas programmé explicitement « si on tombe dans tel cas, alors produire tel résultat ». Il est un peu galvaudé, car il ne s’agit pas d’un apprentissage au sens humain du terme. Il s’agit de techniques statistiques, basées sur l’analyse des données, qui se classent en 2 catégories : les algorithmes supervisés (l’algorithme doit d’abord « apprendre », c’est-à-dire se calibrer, à partir de jeux de données pour lesquels les résultats sont connus) et non supervisés (l’algorithme est fait pour se débrouiller tout seul).
Un exemple d’algorithme non supervisé simple :
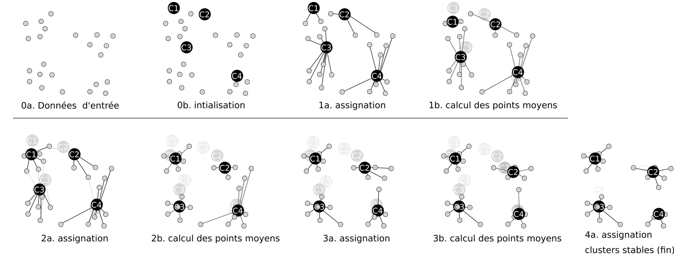
- Les k-moyennes (k-means en anglais) : l’algorithme regroupe les données en k groupes (clusters en anglais) « du mieux possible », ie. En partant de k points aléatoires, il itère et essaie de trouver les k meilleurs regroupements de données voisines en faisant bouger les k centres « dans la meilleure direction de l’itération ». Dans cet exemple, k=4 :
Un exemple d’algorithme supervisé simple :
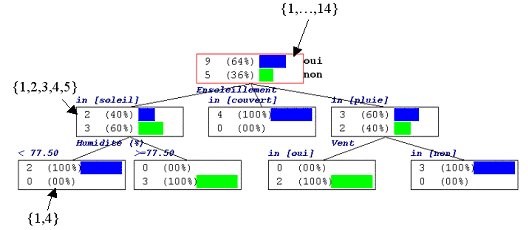
- Les arbres de décision (decision tree) : l’algorithme essaie de trouver le meilleur arbre possible pour organiser les données. Ci-dessous, à partir des statistiques disponibles sur la présence d’une personne au tennis en fonction de la météo, l’algorithme a construit le meilleur arbre de décision possible, ie. Celui avec lequel il faut parcourir le moins de chemin possible pour répondre à des questions de type « quelle est la probabilité que cette personne aille au tennis s’il pleut et qu’il y a du vent ? »
On voit bien que les algorithmes ci-dessus ne sont pas « intelligents » au sens humain du terme, c’est-à-dire qu’ils ne comprennent ni ce qu’ils sont en train de faire, ni la nature des données sur lesquelles ils travaillent. A l’heure actuelle, quand on parle d’IA, on parle uniquement de « deep learning », ie. De réseaux de neurones complexes ayant un grand nombre de couches. Nous allons voir qu’en un sens, un réseau de neurones acquiert la compréhension de ce qu’il fait. Il faut avoir l’esprit large pour faire cette interprétation, car le réseau ne sait pas expliquer ses décisions, ie. Pourquoi il a décidé de tenir plus ou moins compte de telle ou telle donnée, et nous ne pouvons pas non plus le comprendre. Mais la recherche progresse à pas de géants, et nous ne sommes pas à l’abri de découvertes majeures.
Il existe plusieurs types de réseaux de neurones, et la plupart sont supervisés. Les résultats les plus bluffants sont obtenus avec les réseaux non supervisés, comme Alpha Go Zero, puisqu’ils apprennent réellement tout seuls, développent leurs propres concepts (« features » en anglais), et peuvent donc « dépasser l’être humain ».
Le schéma ci-dessous représente le modèle le plus simple, celui qui a été inventé dans les années 1940 et perfectionné dans les années 1970. Même sans savoir comment il fonctionne (les explications arrivent plus loin), on devine en voyant le schéma que chaque nœud fait des calculs complexes, et que plus réseau est profond, plus grand est le besoin en puissance de calcul et en mémoire :
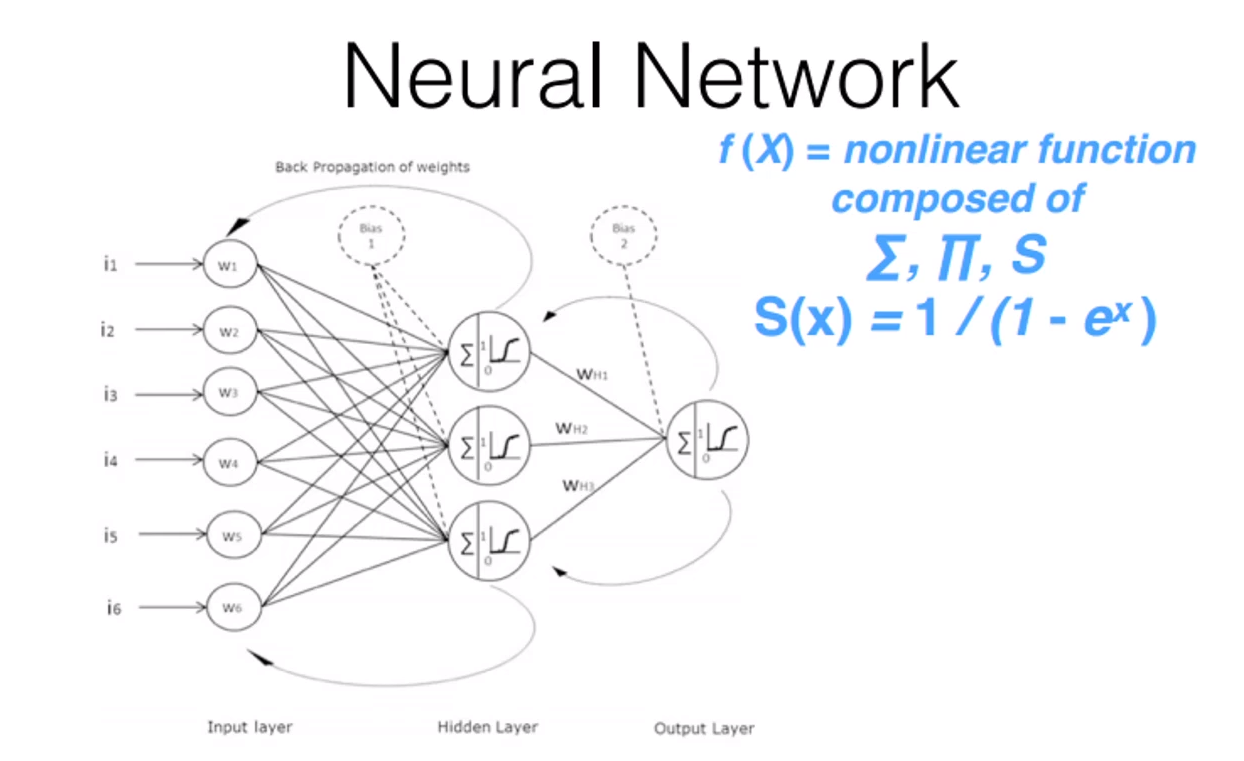
Le besoin en puissance de calcul
Jusqu’en 2000 – 2010, le sujet de l’intelligence artificielle était limité à la recherche scientifique, car les temps de calcul étaient trop longs, voire impossibles faute de place en mémoire. Mais depuis quelques années, la puissance de calcul disponible permet à l’industrie de mettre en pratique ces algorithmes, et de tester toutes sortes d’idées, de plus en plus gourmandes et performantes. La vitesse de progression est exponentielle : la recherche scientifique se nourrit des progrès de l’industrie, et vice-versa, et le sujet intéresse de plus en plus d’acteurs, car le besoin en « intelligence générique » est universel.
Il est à noter que les résultats progressent extrêmement vite, en grande partie grâce à l’amélioration des algorithmes. En définitive, la puissance de calcul permet de tester davantage d’idées, et de sélectionner plus rapidement les meilleures.
Actuellement, la puissance de calcul vient des GPU (Graphic Processing Unit), les cartes graphiques dédiées aux jeux vidéo. En particulier, le fabricant de cartes graphiques NVidia a développé une API baptisée CUDA permettant aux programmeurs d’utiliser leurs cartes graphiques pour effectuer des calculs mathématiques. Ces cartes sont spécialisées dans les calculs matriciels à virgule flottante, ce qui est parfait pour les réseaux de neurones, mais aussi pour la chimie et la biologie par modélisation numérique, la mécanique des fluides numérique… La toute nouvelle est la Tesla P100, et elle est spécialement étudiée pour le deep learning. Voici un benchmark de juin 2016, basé sur des simulations de champs de force autour de biomolécules :
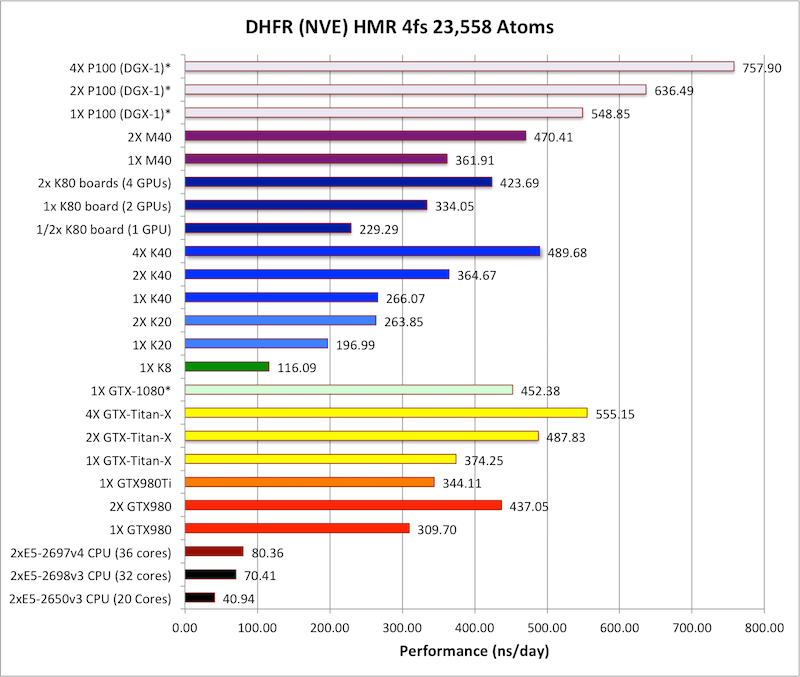
La GTX-Titan-X à 1000 €, une carte graphique haut de gamme pour gamers exigeants, n’est pas si mal placée par rapport au top du deep learning, la P100 à 7500 €.
Détail amusant : Google fabrique ses propres cartes, baptisées TPU (Tensor Processing Unit), qui sont légèrement meilleures que la K40. Nvidia est donc le meilleur, pour l’instant.
Par ailleurs, il est possible d’utiliser la puissance disponible dans le Cloud. Pour quelques euros par mois, on peut par exemple louer des serveurs multi-GPU Tesla K80 (la version précédant la P100) dans AWS P2, le Cloud Amazon dédié à ce type de machines. En plus d’une capacité de calcul extensible quasiment à l’infini (moyennant finances !), on dispose de la capacité de stockage S3 de AWS, elle aussi quasi infinie, ce qui est bien pratique, car les jeux de données peuvent être énormes. Cerise sur le gâteau : la gestion des machines est prise en charge (maintenance des OS, sauvegardes…).
Evidemment, les autres grands acteurs ne sont pas en reste, chacun ayant ses avantages concurrentiels propres. Par exemple, Microsoft Azure propose l’API la plus performante en temps de réponse avec CNTK, car elle est écrite entièrement en C++, un langage plus rapide que le Python qu’on rencontre habituellement.
Les applications de l’IA
Les applications sont innombrables, dans tous les domaines, même les plus inattendus. De façon générale, les IA sont spécialisées dans leur domaine, et, dans ces domaines, elles obtiennent désormais des résultats supérieurs aux humains.
On pense évidemment aux voitures qui se conduisent seules (Google Car, Uber…) :
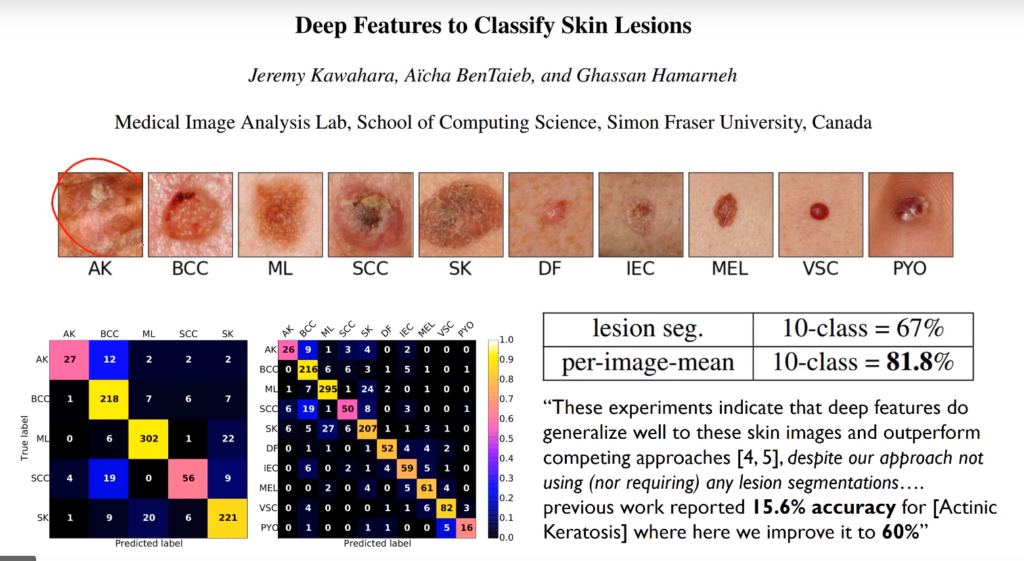
Ou à l’imagerie médicale : ici, il s’agit de lésions de la peau, mais c’est vrai pour tous les sujets (radiographies, prédictions des risques de cancer, Alzeimer, etc…) :
Ou aux assistants comme Siri (iPhone) ou Cortana (Windows). Préparez-vous, la prochaine génération arrive ! La startup Néo-Zélandaise « Soul Machines » développe des assistants doués d’empathie. Jamais fatigués, ils sont toujours là pour vous, avec le sourire, et leur apparence ressemble à la nôtre. L’auteur de l’article, directrice de l’innovation chez Sales Force, était effrayée à l’idée qu’une IA puisse la remplacer, car son métier tourne justement autour de la communication :
« My job is to lead businesses through a human-centered design process », nous dit-elle, « Because my job is about generating actionable insights from user research, I’ve long believed it was safe from the onslaught of artificial intelligence. That was because a lot of what I do involves generating empathy and transferring that empathy from a research setting into a board room. I was wrong. Here is an AI that could soon be a more efficient and reliable researcher than a human can. »


Le Deep Learning donne également de meilleurs résultats que les autres algorithmes dans l’analyse des données. De ce fait, on trouve du Deep Learning chez tous les acteurs qui font du « data mining », à commencer par les grands acteurs du Web. Ci-dessous, la pile technologique de Google Cloud pour le Big Data. La partie qui nous intéresse s’appelle « ML » (Machine Learning), et elle est connectée avec les autres briques. Détail intéressant : elle fonctionne en mode « serverless », c’est-à-dire que les programmeurs y envoient leur code informatique, sans savoir où il va s’exécuter. Le Cloud se charge de la « scalabilité », ie. Il déploie l’exécution du code sur autant de machines qu’il faut, en fonction du besoin en CPU à chaque instant.

Les autres acteurs proposent eux aussi un mode serverless, que chacun peut utiliser, moyennant un prix assez faible : Lambda chez Amazon, Azure Functions chez Microsoft… N’importe qui peut donc apprendre à utiliser ces Cloud, et à tirer parti de leur flexibilité et de leur puissance quasi-illimitée. Evidemment, il faut quand même s’y connaitre en programmation, ce n’est pas réellement à la portée de n’importe qui, et il faut surveiller la consommation générée dans le cloud, sinon gare à la facture en fin de mois !
La recherche scientifique dans le privé et le public
Les grands acteurs du Web mettent de l’IA partout : analyse des données, prédictions statistiques, analyse du langage, traduction instantanée, assistants comme Siri, Face ID avec l’iPhone X…. La courbe des projets utilisant le Deep Learning chez Google est exponentielle :
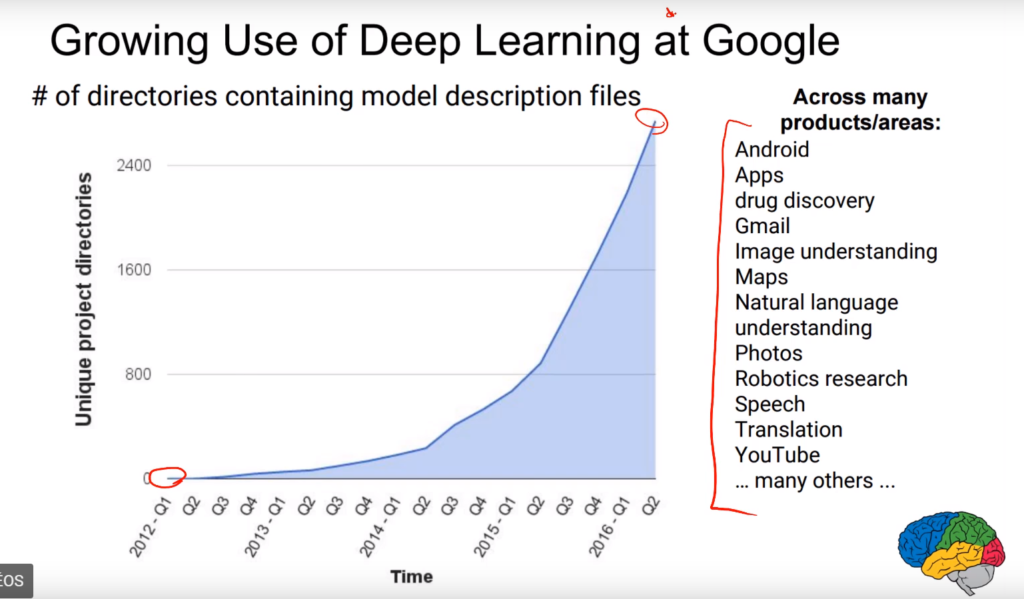
Ils embauchent massivement, à prix d’or. Le salaire moyen chez DeepMind (filiale de Google) est de 345.000 $ / an. Le français Yann Lecun, célèbre pour avoir inventé les réseaux de neurones convolutifs (CNN) en 1999 est devenu directeur de la recherche chez Facebook. Andrew Ng, pionnier de l’analyse d’image, fondateur de Coursera (un site de Mooc très connu), est devenu directeur de la recherche chez Baidu, le Google Chinois.
L’IA mobilise chez Google et Facebook des équipes de recherche fondamentale dont la taille croissante en fait des «mini-CNRS» éclatés à travers le globe. Google, où au total «2 000 ingénieurs travaillant de près ou de loin sur l’IA», compte deux grands labos d’intelligence artificielle en dehors des Etats-Unis à Zurich en Suisse et Bangalore, en Inde.
Facebook qui a ouvert à Paris le «Fair», son laboratoire européen dédié à l’IA, compte également des équipes à New York et dans son siège de Menlo Park, dans la Silicon Valley. De nombreuses voix s’inquiètent déjà d’un rattrapage devenu impossible, tant les moyens déployés par les Gafa pour devenir les premières «IA compagnies» au monde sont sans commune mesure avec ce qui se fait ailleurs. D’où le risque de constitution de nouvelles formes de monopoles intellectuels.
Les gouvernements s’en mêlent aussi, aucun ne voulant être à la traine, et chacun voulant introduire un peu de règlementation dans cette jungle frénétique. Les universités Chinoises et les Américaines investissent massivement, soutenues par leurs gouvernements, et les Français s’y mettent avec le programme d’investissement « France IA », doté d’un budget de 1.5 milliards sur 10 ans, bien timide comparé aux 10 milliards de dollars d’investissements en R&D et rachats pour les Gafa, sur la seule année 2015.
Bases conceptuelles
Le but des réseaux de neurones est d’essayer de résoudre des problèmes inaccessibles aux techniques de programmation classique. Par exemple, si on veut reconnaitre ce qui a été photographié dans une image, il est inenvisageable d’essayer de le coder avec des « if » (si les pixels sont de telle couleur là et là, et que X, et que Y, c’est sans doute un chat). Même problème avec la compréhension du langage naturel, ou avec une décision à prendre en fonction de la situation : l’arbre des possibilités est trop important pour être codé de façon classique. Comme notre cerveau résout ces problèmes avec une efficacité incroyable (par rapport à une machine !), l’idée est d’essayer de faire un programme d’imitation du cerveau, et de voir si les résultats sont bons.
Le deep learning suppose que les problèmes à résoudre équivalent à une fonction mathématique qui prend en entrée des paramètres chiffrés et produit des résultats chiffrés. Par exemple, pour le langage : en entrée, on a des sons, qu’on peut transformer en nombres (fréquence des sons, etc…), et en sortie, on a les mots, les phrases, et le sens de la phrase (on s’en sort en numérotant tout ça). Pour une traduction : en entrée, on a les mots dans une langue (après les avoir numérotés), et en sortie, on a les mots dans une autre langue. Pour une situation, dans un jeu vidéo, dans la vie courante… : en entrée, on a les éléments qui constituent la situation, et en sortie, on a la décision à prendre ou l’action à effectuer. Etc…
Le réseau de neurones ne connait pas la fonction « idéale ». En fait, personne ne sait s’il existe une fonction « idéale » pour le problème à résoudre, ni à quoi elle pourrait ressembler. Le réseau de neurones part du principe qu’elle existe, et qu’elle est continue dans un espace à n+1 dimensions, n étant le nombre de variables en entrée, et il essaie de s’en approcher autant que possible. Le théorème mathématique de l’universalité prouve qu’un réseau de neurones peut s’approcher autant qu’on le souhaite de n’importe quelle fonction continue. Comme il s’agit d’une approximation, un réseau de neurones produit forcément des probabilités. Un réseau de neurones sûr de lui à 100% est faux, par définition : il fait de « l’overfitting », c’est-à-dire qu’il s’est éloigné du cas général, et s’est trop rapproché de son jeu d’apprentissage.
Par analogie, les humains non plus ne connaissent pas la fonction « idéale », puisque chacun pense et agit différemment. Il est possible de pousser la comparaison humain / machine assez loin, mais chacun pourra en faire son interprétation personnelle, car il n’y a pas de vérité absolue dans le comportement humain, ni probablement dans celui des machines.
Par exemple, les humains et les machines ont chacun leurs limites. Pour les humains : notre culture, notre environnement, notre vécu, conditionnent notre façon de nous comporter. Mais notre comportement a aussi une part innée, qui change difficilement : nous constatons tous les jours que les enfants ne se comportent pas tous de la même façon, dès la naissance. Nous sommes « pré-initialisés » dès le départ, en quelque sorte.
Pour une machine, les biais sont issus du jeu d’apprentissage, qui est forcément limité, donc imparfait, et des réglages effectués par les programmeurs : nous verrons plus loin que le programmeur doit initialiser le réseau avec des « hyper-paramètres » qui restent fixes : nombre de couches, nombres de neurones, taux d’apprentissage, choix de l’algorithme de backpropagation, choix des fonctions d’activation des neurones… Par ailleurs, nous verrons que les réseaux nécessitent une pré-initialisation de leurs synapses. Cette initialisation peut être aléatoire, suivant une formule mathématique précise, ou déterminée par un pré-apprentissage non supervisé, même si cette pratique tend à disparaitre car elle présente un biais initial trop important.
Fonctionnement
Il faudrait un livre entier pour expliquer le fonctionnement des divers types de réseaux de neurones. Il y a de nombreux concepts à aborder, théoriques et pratiques.
J’en donne ici un principe simplifié.
Les réseaux supervisés ont une phase d’apprentissage : il faut leur donner un jeu d’apprentissage, pour lequel les hypothèses et les résultats sont connus. Autrement dit, quelqu’un doit avoir labellisé à la main chaque hypothèse.
Par exemple, si on veut apprendre à un réseau de neurones à reconnaitre des images, il faut constituer un jeu d’apprentissage le plus fourni possible: des chiens, des chats, tout ce qu’on veut lui apprendre, sous diverses poses, de diverses races… De façon à ce qu’il apprenne à reconnaitre une sorte de « cas général du chat », une sorte de « cas général du chien », etc… Et qu’il ait suffisamment de variantes pour pouvoir identifier correctement un nouveau chat inconnu. En itérant sur son jeu d’apprentissage, le réseau de neurone se rapproche petit à petit de la fonction mathématique « idéale » qui prend une image en paramètre et indique en sortie la probabilité que l’image soit un chat, un chien, ou quoi que ce soit d’autre qui fasse partie des labels du jeu d’apprentissage.
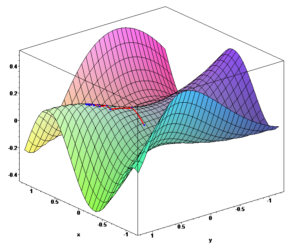
Voici une représentation graphique de l’algorithme d’itération, baptisé « gradient descent », qui est valable pour un seul neurone à la fois. La courbe en 3D s’appelle la « cost function ». Dans cet exemple et dans celui-ci-dessous, le neurone n’a que 2 coefficients, représentés en x et y. En général, un seul neurone a des millions de paramètres, et il est impossible de représenter cette courbe graphiquement. Sur l’axe des z, la « cost function » a pour valeur l’écart entre la fonction mathématique « idéale » et les résultats du neurone, si on lui donne x et y comme valeurs pour ses 2 coefficients. L’itération est représentée par les petits segments en rouge : le principe est de descendre le long de la cost function, et d’arriver à son minimum, car c’est là qu’on trouve les meilleures valeurs possibles pour les coefficients x et y.
Dans un réseau de neurones, il peut y avoir des milliers de neurones, sur plusieurs couches, et il faut utiliser une variante, découverte en 1986 par Geoffrey Hinton, baptisée « backpropagation ». Je ne rentre pas dans les détails, il faudrait plusieurs pages pour l’expliquer, mais le principe est là aussi de trouver le minimum de la cost function du réseau.
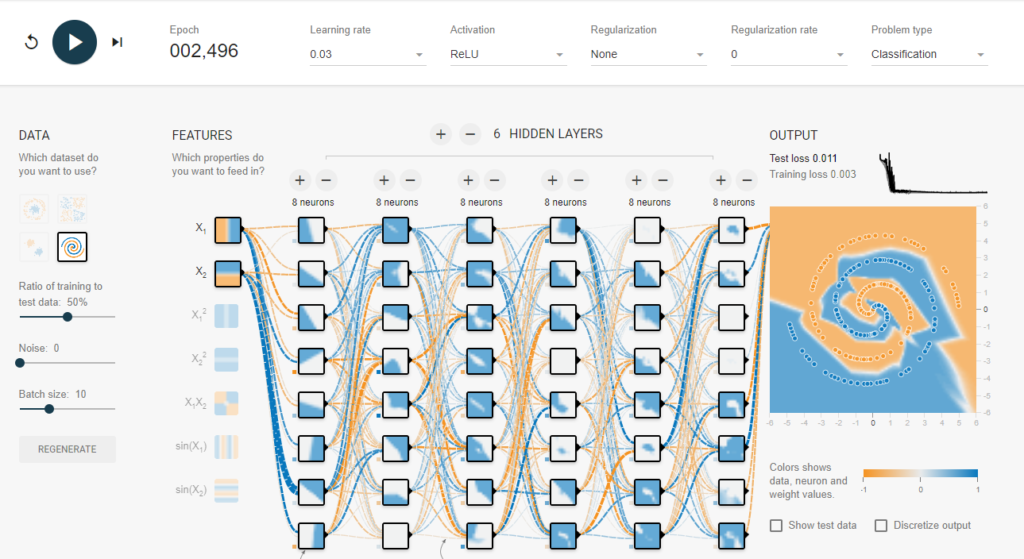
Ici, on peut avoir une représentation graphique du réseau car les points orange et les points bleus dépendent seulement de 2 conditions. Par exemple, il pourrait s’agir d’un problème de type « chaque point correspond à une tumeur ; il est orange si la tumeur est cancéreuse, et bleu sinon ; et on connait sa taille (qui correspond aux abscisses) et son emplacement dans le corps (qui correspond aux ordonnées) ».
En général, ce rendu est impossible, car le réseau travaille dans plusieurs millions de dimensions. Par exemple, s’il doit apprendre à reconnaitre des images de 1000*1000 pixels en couleurs RGB, il travaille en dimension 3.000.001. En effet, chaque image correspond à un point localisé dans un espace de dimension 3.000.001.
Ici, le réseau est constitué d’une couche d’entrée et de 6 couches cachées. Il a appris à séparer les points orange et les points bleus. On voit à l’œil nu qu’avec sa vision d’ordinateur, il n’a pas compris qu’il s’agit d’une spirale, mais il a construit une ligne de séparation, en itérant suffisamment longtemps, à grands coups de formules mathématiques qui ont détecté dans quelle direction aller.
Chaque carré est un neurone : ceux des couches inférieures ont appris des motifs simples, et ceux des couches supérieures fusionnent ces résultats et ont appris des concepts de plus en plus complexes.
Les synapses sont les lignes en pointillés qui relient les neurones. Leur épaisseur indique la force de chaque liaison.
Les différents types de réseaux
Le réseau abordé ci-dessus est le 1er à avoir été inventé : il s’agit du réseau neuronal « classique ».
Principaux défauts : ils demandent une grosse capacité de calculs, ils sont relativement peu efficaces pour des « vrais » problèmes de la vie courante comme la reconnaissance d’image, et ils sont opaques : il est très difficile d’avoir une idée de ce que les neurones ont appris.
Par ailleurs, quand on rajoute trop de couches, le réseau « cale », et n’arrive plus à apprendre correctement. De ce fait, pendant quelques années, le deep learning a eu du mal à se sortir de l’ornière, jusqu’à quelques trouvailles mathématiques que je n’exposerai pas ici.
En 1999, un français, Yann Lecun, a inventé les réseaux convolutifs, qui travaillent en 2 dimensions, et sont beaucoup plus efficaces dans l’analyse d’images, et de façon générale, dans les problèmes pour lesquels la localisation des éléments en 2 dimensions a une importance.
Ces réseaux sont devenus un standard, surtout depuis 2012, car depuis cette date, ils remportent chaque année les concours « ImageNet », dans des versions de plus en plus évoluées.
Pour faire simple, ils calculent des corrélations entre les éléments de l’image, ce qui leur permettent de détecter des schémas significatifs. Les couches inférieures savent reconnaitre des éléments simples (traits, bordures…), et les couches les plus hautes savent reconnaitre des éléments complexes, en fonction de ce qu’on a donné à apprendre : dans les couches hautes, on peut trouver « le neurone de reconnaissance du chien », « le neurone de reconnaissance du chat », etc…
Dernier point intéressant : ils ne sont pas opaques : on peut facilement obtenir une représentation graphique de ce que chaque neurone sait identifier.
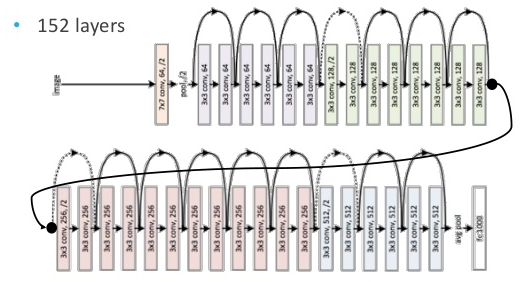
En 2015, le réseau ResNet de Microsoft, qui est une amélioration des réseaux convolutifs, a atteint des performances supérieures aux humains dans la reconnaissance d’images, à l’aide de ses 152 couches ! Il est amélioré chaque année depuis, par des découvertes mathématiques comme « l’identity mapping ».
Alpha Go Zero est une version non supervisée du ResNet de Microsoft : pour effectuer son apprentissage, les chercheurs de Google lui ont seulement fourni les règles du jeu de Go. Les réseaux précédents apprenaient par de gigantesques bases de données de coups et de parties des champions du monde, mais pas Alpha Go Zero. Cela lui a permis de dépasser l’être humain, puisqu’il a fait seul son apprentissage.
En jouant des millions de parties, il se calibre en fonction de ses victoires et de ses défaites. Son apprentissage a été décortiqué par les champions du jeu de Go, car il est passionnant de le voir découvrir des coups joués par les humains, puis les abandonner petit à petit au profit d’autres coups, qu’il juge plus efficaces.
Attention : en réalité, Google a bâti spécifiquement ce réseau pour le jeu de Go, c’est-à-dire qu’il a une architecture neuronale dédiée. Je n’entre pas dans les détails, car il faudrait une dizaine de pages rien que pour ce réseau, mais nous sommes loin de l’intelligence artificielle ultime, capable de résoudre n’importe quel problème…
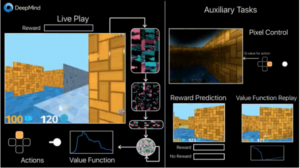
Exemple d’un réseau par renforcement développé par DeepMind qui apprend à jouer à un jeu vidéo, en détectant la récompense associée à ses actions (c’est complexe car la récompense peut arriver longtemps après l’action) :
Nous pouvons également citer les réseaux par récurrence, spécialisés dans la détection de suites logiques, utilisés par exemple pour l’apprentissage du langage. C’est ce type de réseau qui sait « faire de la musique comme les Beattles », par exemple. Je vous renvoie vers « Flow machines », qui a composé « Daddy’s car » en début d’année. Ce n’est pas le tube de l’été, mais ce n’est pas si mal. On trouve des réseaux qui écrivent comme tel ou tel auteur, ou peignent comme tel ou tel peintre…
Attention : ils sont très gourmands en puissance de calcul, et mathématiquement parlant, les formules de calcul sont infernales.
Par exemple, l’université de Washington a créé un réseau récurrent capable de faire des discours comme Barack Obama (vidéo + sons) :
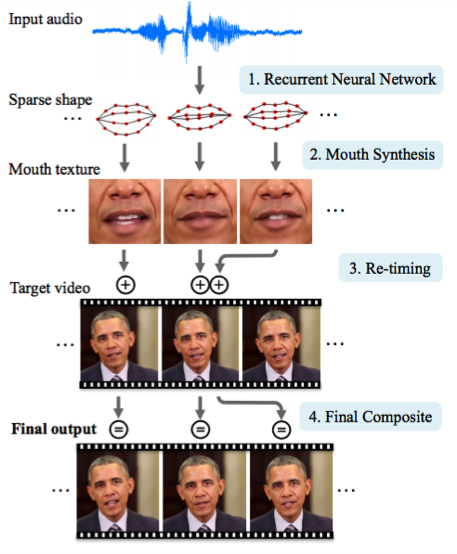
Autre type de réseau : les « region network », qui sont des réseaux convolutifs à détection de bordure. Ils identifient les éléments de l’image en déterminant le cadre le plus probable. Si en plus on les couple avec un réseau par récurrence, ils savent à peu près si ce qu’ils ont trouvé est logique. Par exemple, s’ils ont reconnu un verre sur une table, ils peuvent s’attendre à trouver aussi une assiette, mais pas un paquebot. Une image vaut mieux qu’on long discours :

Gros avantage : leur dernière version, les « super-fast RNN », est suffisamment rapide pour être utilisée en temps réel, par exemple dans les voitures autonomes.
Encore une trouvaille, qui faisait le buzz il y a un an : les « generative adversarial network ». Le principe : un réseau apprend à générer de fausses images, et l’autre apprend à les détecter. A la fin, on obtient un réseau qui sait faire des images plus vraies que nature, et un autre qui sait les détecter mieux qu’un humain.
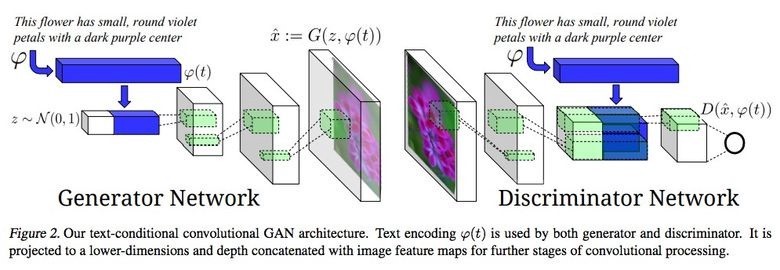
Exemples :

Application inattendue : des petits malins ont appris à générer des mots de passe plausibles pour craquer les systèmes informatiques…
Dernière découverte en date : en novembre 2017, un des pionniers de l’intelligence artificielle, Geoffrey Hinton, a fait le buzz avec un nouveau type de réseau de neurones, les « capsule networks », qui vient corriger certains défauts des réseaux convolutifs. En particulier, les capsule networks savent apprendre la localisation des éléments d’une image : le nez doit être au milieu de la figure, etc… De ce fait, ils apprennent avec beaucoup moins d’exemples, et se rapprochent de l’apprentissage du cerveau humain. Malheureusement, ils sont lents, car ils génèrent une masse de calculs très importante. En attendant les premiers ordinateurs quantiques, ou les premiers processeurs neuronaux ?
Conclusion
Les progrès sont très rapides, la communauté grossit à vue d’œil, mais actuellement l’IA est loin d’être aussi généraliste, efficace et plastique que le cerveau humain.
Nous sommes capables d’abstraction, de créer des stratégies à partir de données incomplètes, et nous « comprenons » nos pensées, c’est-à-dire que nous sommes capables d’expliquer notre raisonnement. Par exemple, nous comprenons le langage, alors qu’actuellement les IA d’analyse du langage naturel fonctionnent essentiellement par statistiques d’apparition des mots. Là où une IA est rigide, notre cerveau est souple, capable de s’adapter et capable d’utiliser ses connaissances dans un nouveau contexte. Par exemple, AlphaGo Zero ne sait pas faire autre chose que jouer au Go ou aux échecs, et il a eu besoin de 29 millions de parties pour atteindre son niveau « super humain ». Là où une IA a besoin de temps pour apprendre et élaborer sa stratégie, le cerveau humain est capable d’en créer une, bien qu’imparfaite, en quelques secondes, sur la base de ses déductions immédiates et/ou des consignes reçues.
Bref, comme le dit Yann Lecun, directeur de l’IA chez Facebook, il est beaucoup trop tôt pour se demander si les robots seront un jour incontrôlables. Pour l’instant, ce domaine relève de la science-fiction. Un bon indicateur des futurs progrès viendra quand les IA sauront faire de l’humour, ou sauront traduire correctement une langue en une autre. Cela signifie qu’elles comprendront le contexte de la situation, et qu’elles sauront faire des projections pertinentes : analyse du langage naturel « réelle » associée à une réelle compréhension de la conversation.
Ceci dit, l’IA est d’ores et déjà plus efficace que l’homme dans les domaines où elle s’est spécialisée. Par exemple dans l’analyse d’image : elle sait faire la différence entre de nombreuses espèces d’animaux. Là où un humain « non spécialiste » voit un chat, elle voit sa race précise. Cela permet d’automatiser de nombreux traitements, qui ne pouvaient jusqu’ici être effectués que par des êtres humains.